
정보처리기사 시험을 준비하는 여러분께 최대 유량 알고리즘의 개념과 주요 알고리즘을 쉽고 자세하게 설명해 드립니다. 복잡한 이론을 넘어 실제 문제 해결에 도움이 되는 핵심 내용만 담았으니, 걱정 말고 따라오세요!
최대 유량 알고리즘: 네트워크 흐름의 비밀

자, 정보처리기사 여러분, 오늘 우리가 파헤쳐 볼 주제는 바로 최대 유량 알고리즘 (Max-Flow Algorithm)입니다! 이름만 들어도 왠지 어려워 보이죠? 하지만 걱정 마세요. 쉽고 재밌게, 그리고 정보처리기사 시험에 꼭 필요한 핵심 내용만 쏙쏙 골라서 설명해 드릴 테니까요!
최대 유량 알고리즘은, 말 그대로 네트워크에서 소스(Source) 노드에서 싱크(Sink) 노드로 흘러갈 수 있는 최대 유량을 찾는 알고리즘입니다. 마치 물이 파이프를 통해 흐르는 것처럼 생각하면 이해하기 쉬워요. 각 파이프는 용량(Capacity)을 가지고 있어서, 한 번에 흘릴 수 있는 물의 양이 제한되어 있죠. 최대 유량 알고리즘은 이러한 제한된 용량을 고려하여, 소스에서 싱크로 최대한 많은 물을 흘려보낼 수 있는 방법을 찾아내는 거예요.
어려운 용어들이 막 등장하긴 했지만, 핵심은 간단합니다. 어떻게 하면 소스에서 싱크까지 최대한 많은 데이터를 효율적으로 전송할 수 있을까? 이 질문에 답하는 것이 바로 최대 유량 알고리즘의 목표입니다. 이 개념을 이해하면, 네트워크 설계, 물류 최적화, 자원 할당 등 다양한 실제 문제에 적용할 수 있는 멋진 능력을 얻게 되는 거죠! 자, 이제 본격적으로 알고리즘을 살펴보기 전에, 필수적인 개념들을 짚고 넘어가도록 하겠습니다.
소스와 싱크, 용량, 유량… 이 용어들이 처음엔 낯설게 느껴질 수도 있지만, 차근차근 알아가다 보면 어느새 술술 이해하게 될 거예요. 걱정하지 마시고, 저를 따라 천천히 한 단계씩 나아가 보자구요! 조금만 더 힘내면, 최대 유량 알고리즘의 달인이 될 수 있답니다! 자, 그럼 다음 단계로 넘어가 볼까요? 흥미진진한 내용들이 기다리고 있으니, 두근두근 설레는 마음으로 함께 탐구해 봅시다! 최대 유량 알고리즘, 정말 매력적인 분야죠?
2.1 용량(Capacity)과 유량(Flow) 이해하기

먼저, 용량과 유량의 차이를 확실히 이해하는 게 중요해요. 간선의 **용량(Capacity)**은 그 간선을 통해 흐를 수 있는 최대 유량을 나타내는 값입니다. 마치 파이프의 지름처럼 생각하면 됩니다. 지름이 크면 더 많은 물이 흐를 수 있겠죠? 반면, **유량(Flow)**은 실제로 그 간선을 통해 흐르고 있는 유량을 나타내는 값입니다. 즉, 용량은 최대치이고, 유량은 현재 흐르고 있는 양이라고 생각하면 됩니다. 물론, 유량은 언제나 용량을 넘어설 수 없어요. 파이프 지름보다 더 많은 물을 억지로 밀어넣을 순 없잖아요?
이 두 개념의 차이를 명확하게 이해해야 최대 유량 알고리즘의 원리를 제대로 파악할 수 있습니다. 용량은 가능한 최대치이고, 유량은 그 제한 내에서 실제로 흐르고 있는 양이라는 점을 꼭 기억해 두세요. 이 차이를 이해하지 못하면, 알고리즘의 핵심적인 개념을 이해하기 어려울 수 있으니 주의하세요! 이 부분이 이해가 되었으면 이제 다음 단계로 넘어가서 포드-풀커슨 알고리즘을 자세히 알아보도록 하겠습니다. 자, 준비되셨나요?
2.2 잔여 용량(Residual Capacity)의 중요성

잠깐! 용량과 유량만 알면 충분할까요? 아니죠! 여기서 핵심 개념 하나 더 등장합니다. 바로 **잔여 용량(Residual Capacity)**입니다. 잔여 용량은 간선의 용량에서 현재 유량을 뺀 값으로, 그 간선을 통해 얼마나 더 많은 유량을 흘릴 수 있는지를 나타냅니다. 마치 파이프에 얼마나 더 많은 물을 흘려보낼 수 있는 공간이 남았는지를 보여주는 척도와 같습니다.
잔여 용량은 최대 유량 알고리즘에서 증가 경로를 찾는 데 매우 중요한 역할을 합니다. 증가 경로는 소스에서 싱크까지 가는 경로 중에 잔여 용량이 모두 0보다 큰 경로를 말합니다. 즉, 유량을 더 흘릴 수 있는 여유 공간이 있는 경로라는 거죠. 이 잔여 용량을 계산하고 관리하는 것이 최대 유량 알고리즘의 효율성을 결정하는 중요한 요소입니다. 잔여 용량이 0이라는 것은 더 이상 그 경로로 유량을 흘릴 수 없다는 의미이니, 잘 기억해 두세요!
잔여 용량 개념을 꼭 기억해야 하는 이유는, 최대 유량을 찾는 과정에서, 간선의 용량을 모두 사용하지 않더라도, 더 이상 유량을 늘릴 수 있는 경로가 없을 수 있기 때문입니다. 이를 파악하기 위해 잔여 용량을 계산하고 확인하는 과정이 필수적입니다. 이제 이 개념을 바탕으로, 다음 절에서 포드-풀커슨 알고리즘을 살펴보겠습니다. 준비되셨죠?
포드-풀커슨 알고리즘 (Ford-Fulkerson Algorithm): 기본 원리와 한계
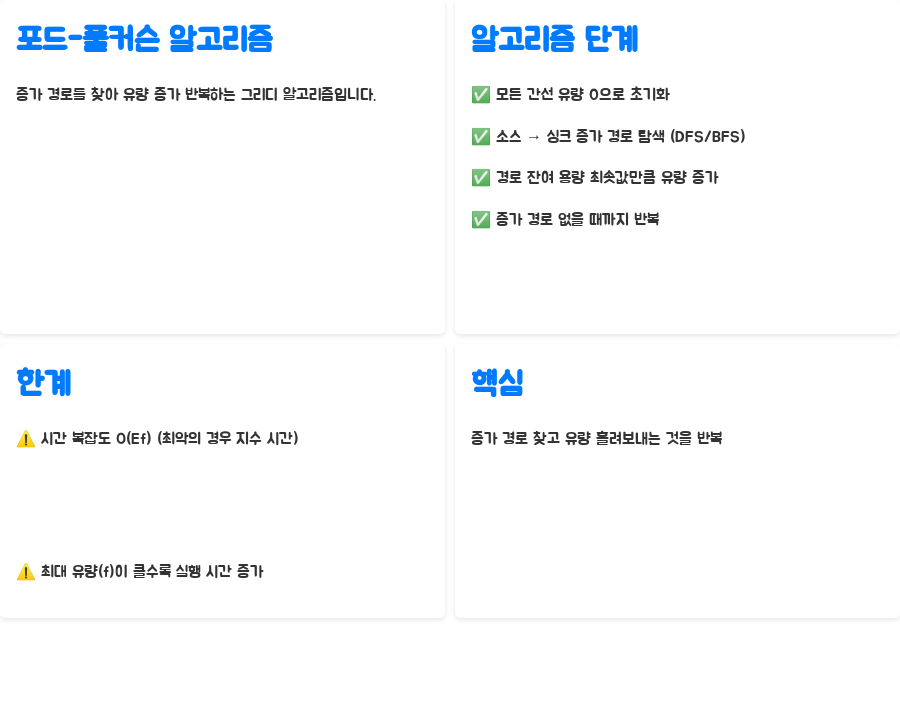
자, 이제 본격적으로 최대 유량 알고리즘의 대표 주자, 포드-풀커슨 알고리즘을 자세히 살펴볼 시간입니다! 이름이 조금 어렵지만, 원리는 의외로 간단합니다. 포드-풀커슨 알고리즘은 증가 경로를 찾아 유량을 증가시키는 과정을 반복하는 그리디 알고리즘입니다. "그리디"라고 하니 왠지 탐욕스러워 보이지만, 실제로는 최적의 해를 찾아가는 효율적인 방법입니다.
알고리즘은 다음과 같은 단계로 진행됩니다. 먼저, 모든 간선의 유량을 0으로 초기화합니다. 그리고, 소스 노드에서 싱크 노드까지의 증가 경로를 찾습니다. 증가 경로는 앞서 설명했듯이, 잔여 용량이 0보다 큰 간선들로 이루어진 경로입니다. 증가 경로를 찾는 데는 DFS나 BFS를 사용할 수 있어요. DFS를 사용하면 깊이 우선적으로 탐색하고 BFS를 사용하면 너비 우선적으로 탐색하죠. 각각의 장단점이 존재하지만, 정보처리기사 시험에서는 BFS를 사용하는 에드몬드-카프 알고리즘을 더 많이 사용합니다.
증가 경로를 찾았으면, 이제 유량을 증가시켜야 합니다. 증가시킬 수 있는 유량의 크기는 경로 상의 간선들의 잔여 용량 중 최솟값입니다. 마치 병목 현상처럼, 가장 좁은 파이프가 전체 유량을 제한하죠. 이 최솟값만큼 유량을 증가시키고, 다시 증가 경로를 찾아 유량을 증가시키는 과정을 반복합니다. 더 이상 증가 경로가 없을 때까지 이 과정을 반복하면, 최대 유량을 찾을 수 있습니다.
하지만 포드-풀커슨 알고리즘은 시간 복잡도가 O(Ef)로, 최악의 경우 지수 시간이 걸릴 수 있다는 단점이 있습니다. 여기서 E는 간선의 개수, f는 최대 유량이죠. 최대 유량 f가 매우 큰 값이라면, 알고리즘의 실행 시간이 비약적으로 증가할 수 있습니다. 이러한 한계 때문에, 실제로는 더욱 효율적인 에드몬드-카프 알고리즘이 더 많이 사용됩니다. 하지만 포드-풀커슨 알고리즘은 최대 유량 알고리즘의 기본 원리를 이해하는 데 매우 중요한 역할을 하므로, 꼭 이해하고 넘어가야 합니다.
포드-풀커슨 알고리즘의 핵심은 증가 경로를 찾고 유량을 흘려보내는 것을 반복한다는 것입니다. 하지만, 이 과정에서 어떤 경로를 선택하느냐에 따라 알고리즘의 효율성이 크게 달라질 수 있다는 점을 명심해야 합니다. 그렇다면, 어떻게 하면 더 효율적으로 증가 경로를 찾을 수 있을까요? 바로 다음에 소개할 에드몬드-카프 알고리즘의 핵심입니다! 자, 다음은 에드몬드-카프 알고리즘에 대한 자세한 설명입니다. 기대해주세요!
에드몬드-카프 알고리즘 (Edmonds-Karp Algorithm): 효율적인 최대 유량 탐색

포드-풀커슨 알고리즘의 단점을 보완한 알고리즘이 바로 에드몬드-카프 알고리즘입니다. 에드몬드-카프 알고리즘은 증가 경로를 찾는 데 **너비 우선 탐색 (BFS)**를 사용합니다. BFS는 최단 경로를 찾는 알고리즘이기 때문에, 에드몬드-카프 알고리즘은 항상 최단 증가 경로를 따라 유량을 증가시킵니다. 이 때문에 최악의 경우에도 O(VE²)의 다항 시간 복잡도를 보장하며, 포드-풀커슨 알고리즘보다 훨씬 효율적입니다. (V는 정점의 개수, E는 간선의 개수)
에드몬드-카프 알고리즘의 핵심은 BFS를 사용하여 최단 증가 경로를 찾는다는 것입니다. BFS를 이용하면, 항상 소스 노드에서 싱크 노드까지의 가장 짧은 경로를 찾을 수 있습니다. 최단 경로를 따라 유량을 흘려 보내면, 더 빠르게 최대 유량에 도달할 수 있다는 장점이 있습니다. 이렇게 최단 경로를 우선적으로 탐색함으로써, 포드-풀커슨 알고리즘에서 발생할 수 있는 지수 시간 복잡도 문제를 해결할 수 있게 되는 거죠.
포드-풀커슨 알고리즘과 비교했을 때 에드몬드-카프 알고리즘의 가장 큰 차이점은 바로 증가 경로 탐색 방식입니다. 포드-풀커슨 알고리즘은 DFS나 임의의 방법을 사용하여 증가 경로를 찾지만, 에드몬드-카프 알고리즘은 BFS를 사용하여 최단 경로를 찾습니다. 이 최단 경로 탐색 방식의 차이가 바로 에드몬드-카프 알고리즘의 효율성을 보장하는 핵심입니다. 이러한 차이점을 명확히 이해하면, 두 알고리즘의 장단점을 비교 분석하여 문제 상황에 맞는 알고리즘을 선택하는 데 도움이 될 것입니다.
에드몬드-카프 알고리즘은 실제로 구현해 보면 포드-풀커슨 알고리즘보다 코드가 조금 더 복잡해 보일 수 있지만, BFS라는 효율적인 탐색 방법을 사용하기 때문에, 훨씬 빠른 속도로 최대 유량을 찾을 수 있습니다. 특히, 대규모 네트워크에서 최대 유량을 찾아야 하는 경우에는 에드몬드-카프 알고리즘의 효율성이 더욱 두드러지게 나타납니다. 정보처리기사 시험에서도 에드몬드-카프 알고리즘은 자주 출제되는 중요한 알고리즘이니, 꼼꼼하게 공부해 두는 것이 좋습니다.
또한, 에드몬드-카프 알고리즘은 증명된 시간 복잡도를 가지고 있어서, 알고리즘의 성능을 예측하고 관리하는 데 유용합니다. 이러한 장점 때문에, 실제 응용 프로그램에서 최대 유량 알고리즘을 구현할 때 에드몬드-카프 알고리즘이 널리 사용되고 있습니다. 이제 에드몬드-카프 알고리즘을 통해 최대 유량 문제를 해결하는 방법을 익혔으니, 다음 단계로 넘어가 실제 문제에 적용해 보는 연습을 해 보도록 하겠습니다. 실전 문제를 통해 이론을 완벽하게 내 것으로 만들어 보세요!
최대 유량 알고리즘 실전 문제 해결 전략
이제 이론 공부는 충분히 했으니, 실전 문제를 통해 최대 유량 알고리즘을 제대로 활용하는 방법을 알아볼까요? 정보처리기사 시험에서는 단순히 이론만 아는 것으로는 부족합니다. 실제 문제에 적용하여 해결하는 능력을 키워야 합니다. 그러려면 다양한 유형의 문제를 풀어보는 것이 가장 중요하죠. 그렇다면 효과적으로 문제를 해결하기 위해서는 어떤 전략이 필요할까요?
우선, 문제를 정확하게 이해하는 것이 가장 중요합니다. 문제에서 주어진 조건들을 꼼꼼하게 읽고, 소스 노드와 싱크 노드, 각 간선의 용량을 정확하게 파악해야 합니다. 만약 조건을 잘못 이해하면, 아무리 좋은 알고리즘을 사용하더라도 틀린 답을 얻을 수 있으니, 주의 깊게 문제를 분석해야 합니다. 문제를 제대로 이해하지 못하면, 아무리 좋은 알고리즘을 사용해도 정답을 얻을 수 없어요. 마치 퍼즐 조각을 맞추는 것처럼, 문제의 조건들을 하나하나 맞춰 나가야 합니다.
문제를 이해했다면, 이제 알고리즘을 선택해야 합니다. 문제의 규모와 특성에 따라 포드-풀커슨 알고리즘과 에드몬드-카프 알고리즘 중 적절한 알고리즘을 선택해야 합니다. 작은 규모의 문제라면 포드-풀커슨 알고리즘을 사용해도 무방하지만, 큰 규모의 문제라면 에드몬드-카프 알고리즘을 사용하는 것이 훨씬 효율적입니다. 어떤 알고리즘을 선택하든, 알고리즘의 원리를 제대로 이해하고 있어야 정확한 답을 얻을 수 있습니다.
알고리즘을 선택했다면, 이제 코드를 작성해야 합니다. 코드를 작성할 때는 가독성과 효율성을 모두 고려해야 합니다. 가독성이 떨어지는 코드는 디버깅하기 어렵고, 효율성이 떨어지는 코드는 실행 시간이 오래 걸릴 수 있습니다. 따라서, 변수 이름을 명확하게 정하고, 주석을 충분히 달아서 코드를 이해하기 쉽게 작성해야 합니다. 또한, 알고리즘의 시간 복잡도를 고려하여 효율적인 코드를 작성하는 것이 중요합니다. 최적의 코드를 작성하기 위해서는 꾸준한 연습과 노력이 필요합니다.
마지막으로, 작성한 코드를 테스트하고 디버깅해야 합니다. 코드를 작성했다고 해서 바로 정답을 얻을 수 있는 것은 아닙니다. 다양한 테스트 케이스를 사용하여 코드를 충분히 테스트하고, 오류가 발생하면 디버깅해야 합니다. 디버깅 과정에서 발생하는 오류들을 해결하는 과정은 알고리즘을 더욱 깊이 이해하는데 도움이 되니, 꼼꼼하게 오류를 수정하는 것이 중요합니다. 이처럼 최대 유량 알고리즘을 활용한 문제 해결은 단순히 코드를 작성하는 것 이상으로, 문제 분석, 알고리즘 선택, 코드 작성, 테스트 및 디버깅 등의 여러 단계를 거쳐야 합니다. 각 단계에서 숙련된 기술과 지식을 필요로 하죠.
| 포드-풀커슨 | 간단한 구현 | 최악의 경우 지수 시간 복잡도 | O(Ef) | 기본 원리 이해에 중요 |
| 에드몬드-카프 | 다항 시간 복잡도 보장 | 구현이 약간 복잡 | O(VE²) | 자주 출제되는 중요 알고리즘 |
알고리즘 장점 단점 시간 복잡도 정보처리기사 시험 관련성
Q1. 포드-풀커슨 알고리즘과 에드몬드-카프 알고리즘의 가장 큰 차이점은 무엇인가요?
A1. 가장 큰 차이점은 증가 경로를 찾는 방식에 있습니다, 포드-풀커슨 알고리즘은 DFS 또는 임의의 방법으로 증가 경로를 찾지만, 에드몬드-카프 알고리즘은 BFS를 사용하여 최단 증가 경로를 찾습니다, 이 차이로 인해 에드몬드-카프 알고리즘이 최악의 경우에도 다항 시간 복잡도를 보장하는 반면, 포드-풀커슨 알고리즘은 지수 시간 복잡도를 가질 수 있습니다.
Q2. 잔여 용량(Residual Capacity)이 왜 중요한가요?
A2. 잔여 용량은 각 간선을 통해 얼마나 더 많은 유량을 흘릴 수 있는지를 나타냅니다, 최대 유량 알고리즘은 잔여 용량을 이용하여 증가 경로를 찾고 유량을 증가시키는 과정을 반복합니다, 잔여 용량이 0이라는 것은 더 이상 그 간선으로 유량을 흘릴 수 없다는 의미이므로, 최대 유량을 찾기 위해서는 잔여 용량을 정확하게 계산하고 관리하는 것이 매우 중요합니다.
Q3. 정보처리기사 시험에서 최대 유량 알고리즘은 어떤 유형으로 출제될 수 있나요?
A3. 정보처리기사 시험에서는 최대 유량 알고리즘의 개념과 에드몬드-카프 알고리즘의 원리를 이해하고 있는지를 묻는 문제가 주로 출제됩니다, 실제 코드를 작성하는 문제보다는, 주어진 그래프에 대해 최대 유량을 계산하거나, 알고리즘의 동작 과정을 설명하는 문제가 출제될 가능성이 높습니다, 따라서, 이론적인 개념을 확실히 이해하고, 다양한 예제 문제를 풀어보면서 실력을 키우는 것이 중요합니다, 단순히 이론만 아는 것보다 실제 문제에 적용해보는 연습이 중요합니다.
이제 최대 유량 알고리즘에 대해 충분히 이해했으면 좋겠습니다, 꾸준한 연습과 문제풀이를 통해 실력을 향상시키고, 정보처리기사 시험에서 좋은 결과를 얻으시길 바랍니다, 화이팅!



