
LRU(Least Recently Used) 알고리즘: 정보처리기사를 위한 심층 분석
메타 설명: 정보처리기사 시험을 준비하는 여러분을 위해 LRU(Least Recently Used) 알고리즘을 완벽하게 정복할 수 있도록 개념, 동작 원리, 장단점, 그리고 실제 활용 예시까지 꼼꼼하게 알려드립니다. 어려운 개념도 쉽고 재밌게 이해할 수 있도록 돕는 친절한 가이드!
LRU 알고리즘: 개념과 동작 원리 파헤치기

LRU, 즉 Least Recently Used 알고리즘은 뭐냐구요? 쉽게 말해서, 가장 최근에 사용되지 않은 데이터를 먼저 버리는 아주 효율적인 메모리 관리 기법이에요. 컴퓨터는 메모리가 무한정 많지 않잖아요? 그래서 자주 쓰는 데이터는 남겨두고, 덜 쓰는 데이터는 과감하게 버려서 메모리를 효율적으로 사용하는 거죠. 마치 냉장고 정리하는 것과 비슷하다고 생각하면 이해하기 쉬울 거예요. 오래된 음식은 과감하게 버리고, 자주 먹는 재료는 눈에 잘 보이는 곳에 두는 것처럼 말이죠. 그런데 이게 단순한 비유가 아니라는 거! 이 원리가 실제로 컴퓨터 시스템의 성능을 엄청나게 향상시키는 비결이랍니다. 어떻게 그럴 수 있는지, 좀 더 자세히 들여다볼까요?
요즘 컴퓨터는 엄청나게 빠른 속도로 움직이지만, 메모리 자체의 속도는 하드디스크나 SSD에 비해 훨씬 빠르거든요. 그 차이가 엄청나서, 메모리에 데이터가 있으면 프로그램이 훨씬 빨리 실행되는데, 이 LRU 알고리즘이 바로 그 속도를 책임지는 주역 중 하나에요. 만약 메모리에 필요한 데이터가 없다면? 하드디스크나 SSD에서 불러와야 하는데, 이 과정이 시간이 엄청 걸리죠. 그래서 메모리에 자주 쓰는 데이터를 최대한 많이 유지하는 것이 중요하고, LRU 알고리즘은 그걸 가장 효율적으로 해내는 방법 중 하나인 거죠. 물론, 이 알고리즘도 완벽하지는 않아요. 가끔 예측이 빗나가서 엉뚱한 데이터를 버리는 경우도 있지만, 대부분의 상황에서는 훌륭하게 작동해서 시스템 성능을 최적화한답니다. 정말 놀랍지 않나요?
그럼 LRU 알고리즘은 어떻게 동작할까요? 간단하게 설명하면, 데이터에 접근할 때마다 그 데이터의 사용 시간을 기록하고, 메모리가 가득 차면 가장 오랫동안 사용되지 않은 데이터부터 삭제하는 방식이에요. 마치 최근에 사용한 앱을 쉽게 찾을 수 있도록 정렬해주는 스마트폰과 같다고 생각하면 이해가 쉬울 거예요. 자주 사용하는 앱은 상단에 위치하고, 오랫동안 사용하지 않은 앱은 아래쪽으로 내려가죠. LRU 알고리즘도 마찬가지로, 최근에 사용된 데이터를 우선적으로 메모리에 유지하고, 오랫동안 사용되지 않은 데이터는 메모리에서 제거하여 새로운 데이터를 위한 공간을 확보합니다. 이렇게 함으로써, 시스템은 항상 가장 필요한 데이터에 빠르게 접근할 수 있게 되는 거죠. 참 똑똑한 알고리즘이죠?
LRU 알고리즘의 핵심은 데이터의 접근 시간을 효율적으로 관리하는 것이에요. 이를 위해 일반적으로 해시 테이블과 이중 연결 리스트를 함께 사용하는데, 해시 테이블은 데이터를 빠르게 찾는 데 사용하고, 이중 연결 리스트는 데이터의 접근 순서를 기록하여 가장 최근에 접근하지 않은 데이터를 쉽게 찾아 삭제할 수 있게 해줍니다. 이러한 자료구조의 조합은 LRU 알고리즘의 효율성을 극대화하는 핵심 요소라 할 수 있죠. 해시 테이블과 이중 연결 리스트의 특징을 잘 이해하고 있다면, LRU 알고리즘의 구현 원리를 더욱 쉽게 이해할 수 있을 거예요. 이 부분은 다음 섹션에서 더 자세하게 다뤄보도록 하겠습니다.
자, 이제 LRU 알고리즘의 기본적인 동작 원리에 대한 이해도가 높아졌을 거라고 생각해요. 다음 섹션에서는 LRU 알고리즘의 실제 구현과 관련된 내용, 그리고 장단점에 대해서도 좀 더 자세하게 알아보도록 하겠습니다. 기대해주세요!
LRU 알고리즘 구현 및 장단점 분석: 현실적인 적용과 한계
자, 이제 LRU 알고리즘을 실제로 어떻게 구현하는지, 그리고 이 알고리즘의 장점과 단점은 무엇인지 자세히 살펴보도록 하겠습니다. 이론적인 이해만큼 중요한 것이 바로 실제 구현과 그에 따른 효과와 한계를 아는 것이죠. 이 부분을 확실히 이해해야 정보처리기사 시험에서도 좋은 점수를 받을 수 있을 거예요!
LRU 알고리즘을 구현하는 방법은 여러 가지가 있지만, 가장 일반적인 방법은 앞서 언급했던 해시 테이블과 이중 연결 리스트를 결합하는 방식입니다. 해시 테이블은 데이터에 대한 빠른 접근을 제공하고, 이중 연결 리스트는 데이터의 최근 사용 순서를 효율적으로 관리합니다. 데이터가 요청될 때, 해시 테이블을 통해 데이터를 빠르게 찾고, 그 데이터를 이중 연결 리스트의 가장 앞으로 이동시킵니다. 이렇게 함으로써 최근에 사용된 데이터가 항상 리스트의 앞쪽에 위치하게 되고, 가장 오래된 데이터는 리스트의 맨 뒤에 위치하게 되죠. 메모리가 가득 차면, 이중 연결 리스트의 맨 뒤에 있는 데이터(가장 최근에 사용되지 않은 데이터)를 제거하면 되는 거죠. 이 방법은 데이터 삽입과 삭제 연산 모두 O(1) 시간 복잡도를 가지기 때문에 매우 효율적입니다.
하지만, 모든 알고리즘이 그렇듯이, LRU 알고리즘에도 단점은 존재합니다. 가장 큰 단점은 바로 오버헤드입니다. LRU 알고리즘은 각 데이터의 접근 시간을 기록하고 관리해야 하기 때문에, 메모리와 연산 시간 측면에서 추가적인 부담이 발생할 수 있습니다. 데이터의 크기가 크거나 접근 빈도가 높은 경우 이러한 오버헤드는 무시할 수 없을 정도로 커질 수도 있죠. 하지만, 현실적으로 LRU 알고리즘의 장점, 즉 빠른 데이터 접근 속도는 이러한 오버헤드를 상쇄하고도 남을 만큼 큰 이점을 제공합니다. 따라서, 메모리 공간이 제한적이고 빠른 데이터 접근 속도가 중요한 시스템에서는 LRU 알고리즘이 여전히 최고의 선택이 되는 경우가 많아요.
LRU 알고리즘의 또 다른 단점으로는, 실제 데이터 접근 패턴을 완벽하게 예측하지 못한다는 점입니다. LRU 알고리즘은 과거의 접근 패턴을 기반으로 미래의 접근 패턴을 예측하지만, 실제 데이터 접근 패턴은 매우 동적이고 예측 불가능한 경우가 많습니다. 때문에, LRU 알고리즘이 항상 최적의 성능을 보장하는 것은 아니에요. 실제로는 LRU 알고리즘보다 더욱 복잡하고 정교한 알고리즘들이 존재하며, 어떤 알고리즘을 사용하는 것이 가장 효율적인지는 시스템의 특성과 데이터 접근 패턴에 따라 달라집니다.
그럼에도 불구하고, LRU 알고리즘은 단순하면서도 효과적인 메모리 관리 기법으로, 다양한 응용 분야에서 널리 활용되고 있습니다. 특히, 웹 브라우저의 캐시 관리, 운영체제의 페이지 교체 알고리즘, 데이터베이스의 버퍼 관리 등에서 그 효용성을 톡톡히 발휘하고 있죠. 하지만, LRU 알고리즘을 적용할 때는 그 장점과 단점을 모두 고려하여 시스템의 특성에 맞게 적절하게 사용해야 한다는 점을 기억해야 합니다. 특히, 정보처리기사 시험에서는 이러한 장단점에 대한 이해를 묻는 문제가 자주 출제되니, 꼼꼼하게 공부하는 것이 중요해요!
이 섹션에서는 LRU 알고리즘의 실제 구현 방식과 장단점에 대해 살펴보았습니다. 다음 섹션에서는 LRU 알고리즘의 실제 활용 사례를 몇 가지 소개하고, 마지막으로 FAQ를 통해 여러분이 궁금해할 만한 질문들을 미리 답변해 드리도록 하겠습니다.
LRU 알고리즘의 실제 활용 사례: 웹 브라우저부터 운영체제까지
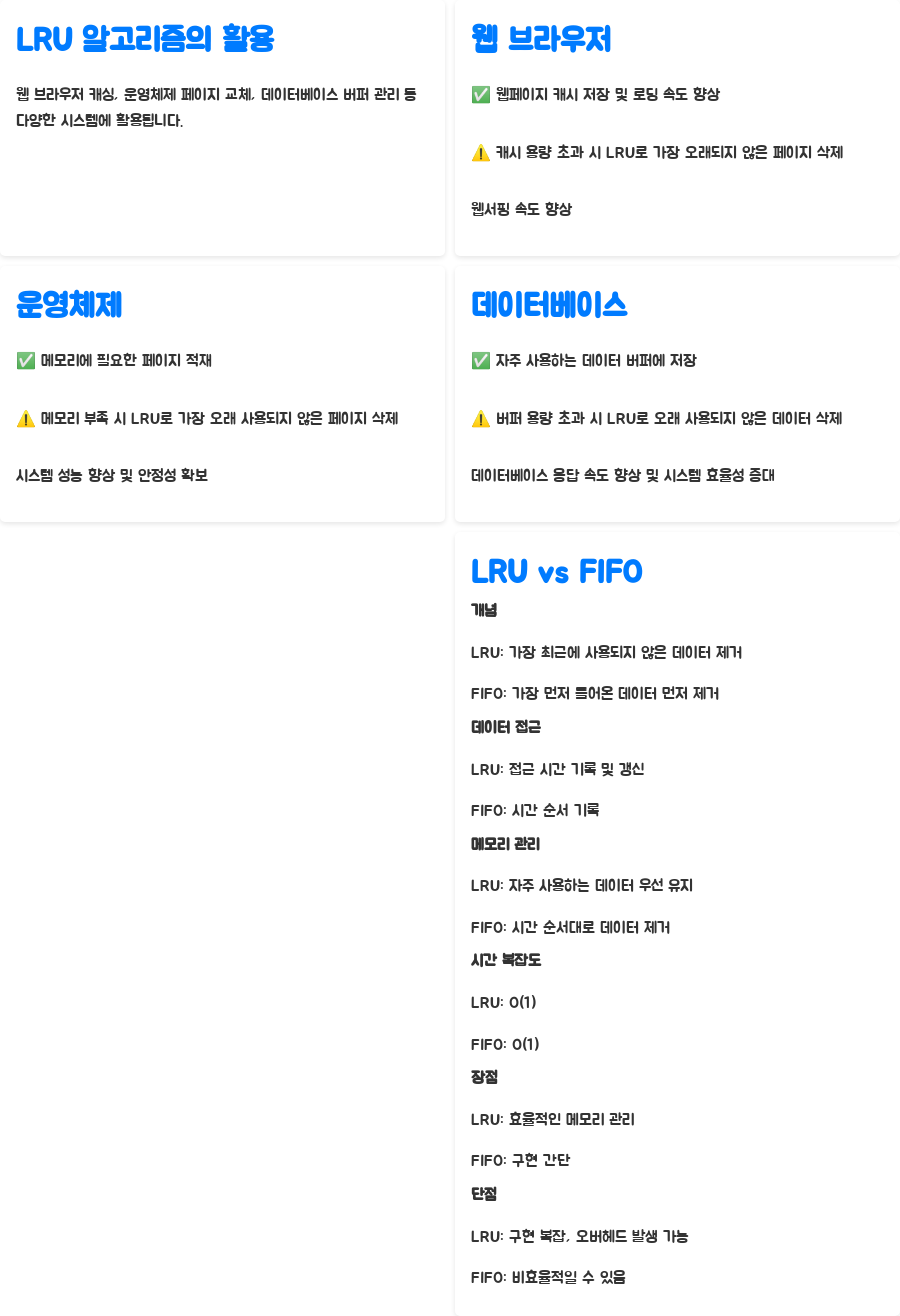
LRU 알고리즘은 이론적인 개념을 넘어서, 우리 주변의 다양한 시스템에서 실제로 활용되고 있습니다. 웹 브라우저의 캐싱, 운영체제의 페이지 교체, 그리고 데이터베이스 시스템의 버퍼 관리 등이 대표적인 예시죠. 이러한 시스템에서 LRU 알고리즘은 어떻게 사용되고 있으며, 어떤 효과를 가져오는지 자세히 살펴보도록 하겠습니다.
웹 브라우저는 사용자가 방문한 웹페이지의 내용을 캐시에 저장하여, 사용자가 같은 페이지를 다시 방문할 때 로딩 속도를 높입니다. 만약 캐시 용량이 제한되어 있다면, LRU 알고리즘을 통해 가장 오랫동안 사용되지 않은 페이지의 캐시를 삭제하고 새로운 페이지의 캐시를 저장하는 방식을 사용합니다. 이를 통해 사용자가 자주 접근하는 페이지는 빠르게 로드되고, 오랫동안 사용하지 않은 페이지는 메모리를 차지하지 않도록 관리하여 브라우저의 성능을 향상시키죠. 덕분에 우리는 웹서핑을 더욱 빠르고 원활하게 즐길 수 있는 거예요! 생각해보면, 우리가 매일 사용하는 웹 브라우저도 LRU 알고리즘이라는 멋진 기술 덕분에 원활하게 작동하는 거랍니다.

운영체제에서도 LRU 알고리즘은 메모리 관리에 중요한 역할을 합니다. 운영체제는 프로세스가 필요로 하는 페이지를 메모리에 적재하는데, 메모리가 부족할 경우 LRU 알고리즘을 사용하여 가장 오랫동안 사용되지 않은 페이지를 메모리에서 삭제하고 새로운 페이지를 적재합니다. 이 과정은 사용자에게는 투명하게 이루어지지만, 시스템 성능에 큰 영향을 미칩니다. 만약 LRU 알고리즘을 사용하지 않는다면, 메모리 부족으로 인해 시스템이 느려지거나 심지어는 작동하지 않을 수도 있죠. 그래서 운영체제의 안정적인 동작을 위해 LRU 알고리즘은 필수적인 요소라고 할 수 있어요. 이렇게 우리가 무심코 사용하는 운영체제의 안정성 뒤에는 LRU와 같은 복잡한 알고리즘이 숨겨져 있다는 사실이 놀랍지 않나요?
데이터베이스 시스템에서도 LRU 알고리즘은 버퍼 관리에 사용됩니다. 데이터베이스 시스템은 자주 접근하는 데이터를 버퍼에 저장하여 디스크 접근 횟수를 줄이고 성능을 높입니다. 버퍼의 크기가 제한적일 때는 LRU 알고리즘을 이용하여 가장 오랫동안 사용되지 않은 데이터를 버퍼에서 제거하고, 최근에 사용된 데이터를 저장합니다. 이는 데이터베이스의 응답 속도를 빠르게 하고 시스템의 전반적인 효율성을 높이는 데 크게 기여합니다. 이처럼 LRU 알고리즘은 우리가 매일 사용하는 다양한 IT 시스템의 성능 향상에 핵심적인 역할을 하고 있습니다. 우리가 이러한 시스템을 편리하게 사용할 수 있는 것은 모두 이런 알고리즘 덕분이라는 것을 잊지 말아야 할 거 같아요. 실제로 우리가 사용하는 수많은 시스템들이 LRU 알고리즘에 의존하고 있으니, 그 중요성을 새삼 느낄 수 있겠죠?
| 개념 | 가장 최근에 사용되지 않은 데이터를 제거 | 가장 먼저 들어온 데이터를 먼저 제거 |
| 데이터 접근 | 접근 시간 기록 및 갱신 | 시간 순서 기록 |
| 메모리 관리 | 자주 사용하는 데이터 우선 유지, 덜 쓰는 데이터 제거 | 시간 순서대로 데이터 제거 |
| 시간 복잡도 | O(1) | O(1) |
| 장점 | 데이터 접근 패턴에 따라 효율적인 메모리 관리 가능 | 구현이 간단함 |
| 단점 | 구현이 복잡하고 오버헤드 발생 가능 | 데이터 접근 패턴을 고려하지 않아 비효율적일 수 있음 |
기능 LRU 알고리즘 FIFO 알고리즘
FAQ: LRU 알고리즘에 대한 궁금증 해결
Q1. LRU 알고리즘과 FIFO 알고리즘의 차이점은 무엇인가요?
A1. LRU 알고리즘은 가장 최근에 사용되지 않은 데이터를 제거하지만, FIFO(First-In, First-Out) 알고리즘은 가장 먼저 들어온 데이터를 먼저 제거합니다, 즉, LRU는 데이터의 사용 빈도를 고려하는 반면, FIFO는 시간 순서만을 고려하기 때문에, LRU가 일반적으로 더 효율적인 성능을 제공합니다, FIFO는 구현이 간단하지만, LRU는 데이터 접근 패턴을 더 잘 반영하여 페이지 부재율을 낮추는 데 더 효과적이에요.
Q2. LRU 알고리즘의 시간 복잡도는 어떻게 되나요?
A2. 일반적인 LRU 알고리즘 구현(해시 테이블과 이중 연결 리스트 사용)의 경우, 데이터 검색(get), 삽입(put), 삭제 연산 모두 평균적으로 O(1)의 시간 복잡도를 가집니다, 이는 매우 효율적인 성능을 의미하며, 대량의 데이터를 처리하는 시스템에서도 효과적으로 작동할 수 있다는 것을 보여줍니다.
Q3. LRU 알고리즘은 어떤 경우에 가장 효과적일까요?
A3. LRU 알고리즘은 데이터 접근 패턴이 지역성(Locality of Reference)을 보이는 경우에 가장 효과적입니다, 지역성이란, 최근에 접근한 데이터에 다시 접근할 확률이 높다는 것을 의미하는데요, 웹 브라우징이나 프로그램 실행 등 많은 애플리케이션에서 이러한 지역성이 나타납니다, 따라서, 이러한 애플리케이션의 캐시 메모리 관리에 LRU 알고리즘을 적용하면 시스템 성능을 크게 향상시킬 수 있습니다, 하지만 데이터 접근 패턴이 예측 불가능하거나 무작위적인 경우에는 다른 알고리즘을 고려하는 것이 좋습니다.
이 글이 정보처리기사 시험 준비에 도움이 되셨기를 바랍니다, 다음에도 유익한 컨텐츠로 찾아뵙겠습니다,



